
En este post aprenderemos qué es el archivo robots.txt, para qué sirve, cómo se puede crear este archivo de forma sencilla y cómo implementarlo en nuestra web.
Una vez tenemos la web desarrollada, al igual que trabajamos el sitemap para mostrarle a los motores de búsqueda la estructura de contenido de nuestra nueva web, también debemos tener en cuenta el tan conocido archivo robots.txt.
¿Qué es el archivo robots.txt?
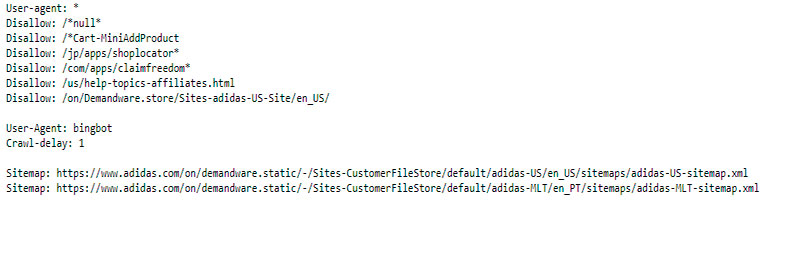
Un archivo robots.txt es un simple documento .txt subido a la raíz de la web bajo el nombre robot.txt y con una estructura concreta que indica a los rastreadores de los motores de búsqueda qué páginas de tu sitio pueden rastrear y cuáles no.
No se utiliza explícitamente para evitar la indexación de una página, aunque la lectura de este archivo por parte de los buscadores está muy relacionado con la indexación del mismo.
¿Cómo funciona robots.txt?
El robots.txt es muy sencillo, aunque no lo parezca. Lo primero que debemos saber es para qué sirve el archivo robots.txt y que funcionalidad tiene.
Utilizamos este archivo para impedir que los robots de algunos buscadores rastreen contenido que no deseamos que indexen ni muestren en sus resultados.
Es decir, con este archivo público, indicamos a los buscadores qué parte o páginas de nuestra web no deben entrar a rastrear. En él, podemos especificar de manera sencilla, los directorios, subdirectorios, URLs o archivos de nuestra web que no deberían ser rastreados o indexados por los buscadores.
¿Cómo creamos el archivo?
Para habilitarlo, solo necesitamos subirlo a la raíz del dominio en formato texto con nombre “robots.txt”.
¿Qué comandos utilizar en el robots y cómo indicarlos?
Los principales comandos que emplearemos en un robots.txt serán
User-agent: son los motores de búsqueda que vas a permitir o denegar que rastreen en tu web. Su sintaxis sería:
Disallow: indica al user agent que no debe acceder, rastrear ni indexar una URL, subdirectorio o directorio concreto.
Allow: es el antónimo a disallow. Permites al user agent a acceder a rastrear las partes de tu web concretas: una URL, subdirectorio o directorio.
Los comandos Allow y disallow solo se aplican a los agentes de usuario que hayamos especificado en la línea anterior a ellas. Puedes incluir diferentes reglas de allow y disallow para diferentes agentes de usuario.
Todo el texto precedido del comando # será un comentario y no será leído por las arañas.
Desde el propio soporte de Google para desarrolladores puedes encontrar toda la información detallada sobre el archivo robots.txt.




Sorry, the comment form is closed at this time.